Localization Techniques for Vision Models in Real Workflows
Improve localization in vision models by combining prompting strategies (order of description), grid-based coordinates, and tiled, coarse-to-fine analysis, optionally using segmentation to isolate objects.
Vision models are interesting because prompting them can be trickier than people expect. We tend to assume that if all the information is “in the scene,” then everything should be equally available to the model. But in practice, a vision model has to break an image down into embeddings. It’s looking for certain kinds of details and compositions, and the way an image gets turned into tokens can vary from system to system.
One of the earliest, cleanest examples of this is the Where’s Waldo-style test: give the model an image where the target object occupies only a small portion of the frame and see if it can find it. It’s a great way to gauge how precise the model is at detection—can it pick out a tiny character in one corner and tell you where it is? Often, a model can tell you something is present, but not precisely where. It’s as if it “remembers” that Waldo exists somewhere in the scene, without retaining specifics about the location.
A related challenge is maze solving. You can give a model a simple maze, then progressively more complicated ones, and ask it to chart a path through. To be clear, this is about a pure vision model working from the image input. Once you add a reasoning system, or the ability to go back and look at the image repeatedly, or a tool that tiles/crops the image for closer inspection, the capabilities can shift significantly.
At its simplest, a vision model is trying to form a general understanding of a scene, shaped by how it was trained and what it learned to focus on. If it was trained on lots of images of animals with labels that just say what animal is present, then it’s probably going to get good at identifying the animal—without necessarily learning fine-grained spatial precision.
That said, there are several ways to work with a vision model—sometimes through prompting alone, and sometimes with light pre-processing—before you jump straight to building heavier software tooling.
One simple prompting trick is to ask the model to describe everything in the scene in the order it notices it. This won’t always be accurate, but it can nudge the model to pay attention to relationships between objects (and between embeddings), which can surface where things are placed relative to each other.
Another is to pre-process the image by overlaying a grid and labeling the cells (letters and numbers). Then you can ask the model for coordinates instead of vague spatial language. For example, you might refer to positions like A1 or F5. The exact reliability is variable and depends heavily on how the model was trained, but it can improve how consistently it talks about location.

If you want to be more systematic, you can test these models on images you’ve already labeled—where you know the ground-truth locations—and score how well the model identifies position. There are entire eval suites built around this idea now, but you can also invent your own tests and explore where a specific model is strong or weak.
A practical way to get more precise localization is tiling: break the image into a series of tiles and run them through the vision model one by one, asking whether a specific object is present in each tile. This often produces much tighter position estimates. The downside is that some objects are larger than a single tile, so it can help to do two passes—first with larger tiles to get a coarse region, then with smaller tiles to refine the location.
Of course, once you start using specialized vision tooling, the game changes. For example, with a fast segmentation model (like Segment Anything 3), you can isolate objects and get their positions quickly, then feed that object/location data—along with the original image—into a vision model for deeper scene understanding: intent, what characters are doing, and the overall gestalt of the scene.
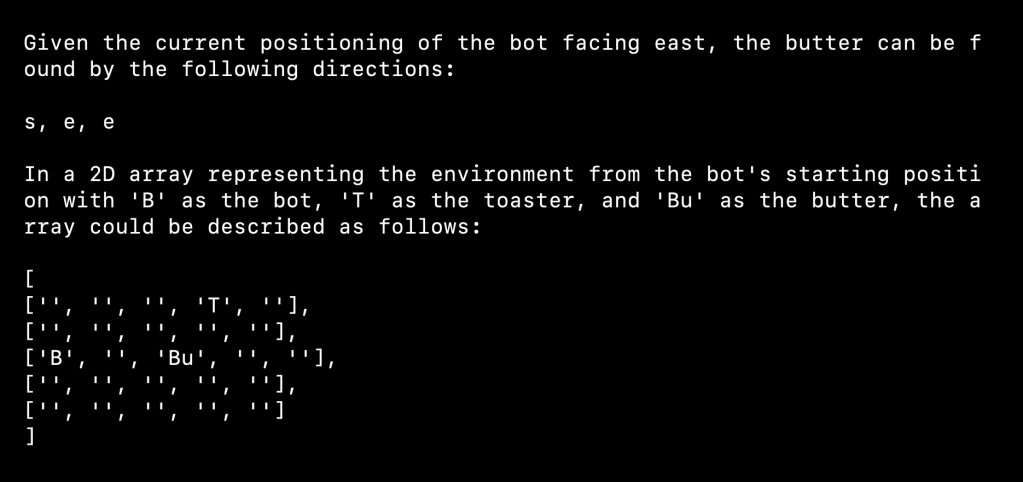
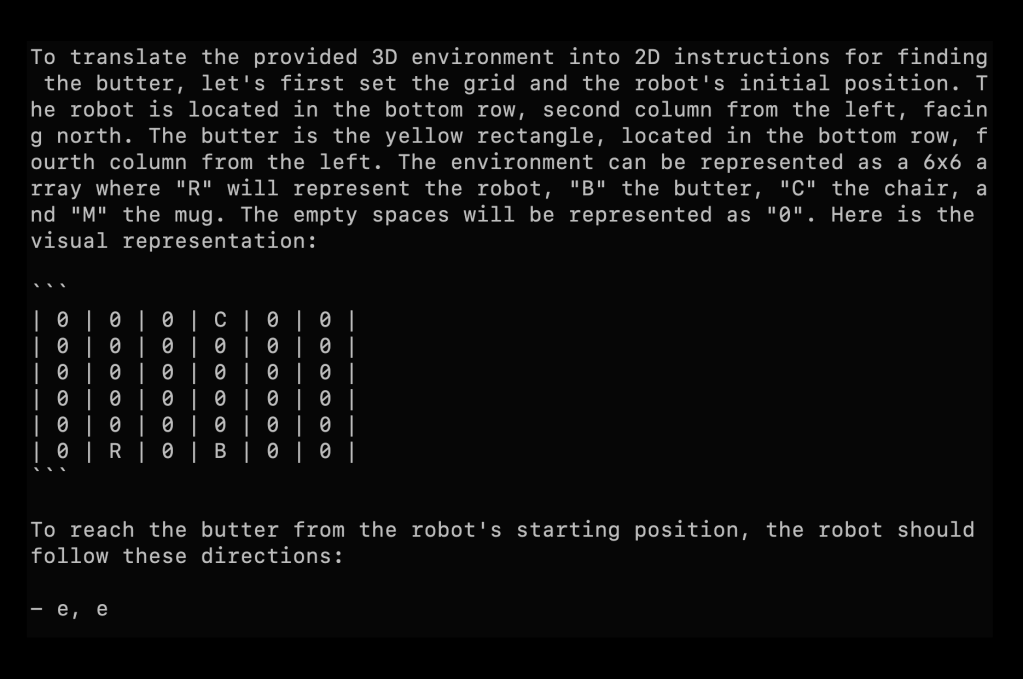
I’ve built a couple applications along these lines just for fun. I have a GitHub repo with a virtual robot rolling around a 3D environment, using a GPT-4-class vision model to try to find objects. It’s slow and not the most effective way to do it, but it’s a neat example of using what is ostensibly a language model to control an agent moving through space and searching visually.
I’ve also used similar techniques on NASA imagery—scanning over Mars data to look for features. Researchers do this for real in far more professional ways, but it’s the same core idea: process a series of images and look for specific patterns or objects.
There are probably a lot of fun projects in this space. In one of my novels, I described using an image model with a tiling function and a map to look for what seemed like submerged cars. People have actually done this with satellite images and found cars in lakes—it happens a lot in Florida. Once you can search at scale, you start to realize how many “hidden in plain sight” problems become approachable.